Como el nombre de este post lo indica, quiero dedicarme un rato a escribir sobre arquitectura de software y a dos de los atributos de calidad más deseados por los arquitectos de medianos y grandes sistemas: escalabilidad horizontal y redundancia. En otro post entonces veremos como la suite de WSO2 enfoca estos temas.
Los usuarios siempre desean que el sistema esté funcionando y que lo haga rápido, algo no siempre fácil de lograr:

Desde el punto de vista de la arquitectura la mejor manera de lograr que un sistema esté siempre online y que funcione adecuadamente es que el mismo sea escalable y además redundante.
A un sistema se le puede incrementar su rendimiento si se añade más hardware para que este pueda correr. En estos casos el sistema se ejecuta en una máquina A y se añade una máquina B, para poder duplicar las prestaciones en general. Si luego se añade una máquina C entonces se triplica su rendimiento. A esto se le llama escalabilidad horizontal. La capacidad de poder añadir nuevo hardware al conjunto sin afectar al sistema que los utiliza.
NOTA: Es bueno aclarar que para que un sistema pueda escalar de esta forma debe haber sido diseñado con esta idea en mente, si no luego se hace un poco complicado lograrlo eficientemente.
Por el lado de las fallas, un sistema no debe verse afectado por la pérdida de uno o más de sus servidores replicados, debe ser capaz de funcionar con al menos 1. Una pérdida de este tipo solo debe afectar el rendimiento. A esto se le llama redundancia.
Entonces de lo que estamos hablando es de tener sistemas, mediados o grandes, que puedan distribuirse entre varios nodos servidores y que se repliquen en estos nodos, de forma tal que la caída de uno o más de ellos no afecte el funcionamiento del sistema.

La pregunta es: ¿Cómo se logra?
La solución:
Balanceo de Carga.

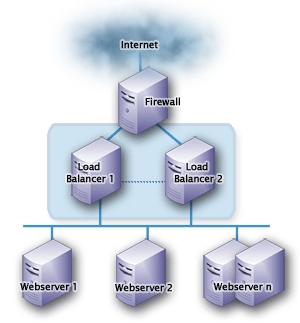
El balanceo de carga no es otra cosa que la técnica de enviar peticiones a recursos, seleccionando el recurso basado en determinado algoritmo (aleatorio, round-robin, aleatorio con pesos, etc). O sea es tener varios lugares con la misma capacidad de realizar una tarea, a los que podamos enviar una petición y seleccionar el lugar adecuado basado en algún criterio.
Esta solución nos permite resolver el problema que aparece cuando tenemos una misma aplicación distribuida por ejemplo en 3 nodos diferentes y nos preguntamos cómo lograr que las peticiones de los usuarios se distribuyan entre los 3 nodos y no siempre lleguen a uno solo. U otro problema sería el de que queremos que todas las peticiones lleguen siempre al mismo nodo pero en caso de que este falle, se envíen a los otros nodos.
Como ven al introducir 3 nodos estamos escalando horizontalmente la aplicación, pero igual necesitamos que los 3 nodos sean usados, y además necesitamos que la información en cada nodo sea la misma porque si estamos trabajando en el "nodo 1″ durante un día y este se cae y pasamos al "nodo 2″, que pasa con la información que generó el "nodo 1″. Vaya problema.
Soluciones de BC:
Para el balanceo de carga existen 3 tipos de soluciones reconocidas:
- Clientes inteligentes: Es cuando un desarrollador se mete a tirar código para manejar como enviar las peticiones a diferentes nodos, subscribirse a nodos, detectar nodos caídos y cosas así. Algo interesante pero que no trabaja bien.
- Hardware para el balanceo de carga: lo más caro del mundo.
- Software para el balanceo de carga: lo mejorcito teniendo en cuenta la relación costo/beneficio. Apache Tomcat tiene su software para el balanceo de carga. REDHAT tiene su solución.
O sea que la solución es buscar un buen software que nos permita realizar configuraciones de cada nodo a donde hay que enviar las peticiones y que cuando estas lleguen las distribuya de forma eficiente.

En el caso específico de Apache Tomcat ellos brindan una muy buena solución para potenciar sistemas escalables y redundantes.
Antes mencionaba algunos algoritmos para el balanceo de carga. Vamos a profundizar un poco más:
DNS Round-Robin:Esta técnica no requiere de hardware ni servidores especiales gestionando el balanceo. Simplemente se le dan varias direcciones IP a cada sitio, y se asume que eso va a dar una distribución pareja de las visitas a cada una de las IP asignadas. (y por supuesto, cada una de ellas en un servidor distinto con los mismos contenidos del mismo sitio, replicado o compartido)
Una contra de este sistema es que en caso de que uno de los servidores salga de servicio, todos los usuarios que tengan esa IP van a perder acceso. A veces se busca resolverlo con herramientas como HeartBeat y Fake.
Una contra de este sistema es que en caso de que uno de los servidores salga de servicio, todos los usuarios que tengan esa IP van a perder acceso. A veces se busca resolverlo con herramientas como HeartBeat y Fake.
LB Round-Robin:Similar al anterior, pero en lugar de hacer una distribución via DNS, hacemos una distribución al azar a través de un balanceador de carga.
Weighted LB:También utilizamos un balanceador de carga, con la diferencia de que en lugar de hacer una distribución al azar se hace contemplando la capacidad (que un administrador debe definir) relativa entre los servidores web del grupo de balanceo.
Dynamic-Weighted LB:En este caso, no se requiere de un administrador definiendo de forma manual la capacidad de cada integrante del grupo de balanceo, sino que el load balancer puede medir y estimar esto por sus propios medios, a través de monitoreos períodicos de los equipos.
Sticky-Sessions o Sticky-User:Asumamos nuevamente que todos los equipos del grupo tienen las mismas características y capacidades, muchas veces es conveniente (y hasta necesario) que un usuario que haya sido derivado a un servidor web determinado, sea derivado nuevamente al mismo servidor web en caso que vuelva a ingresar. Para ello se usan "Sticky-Session" o "Sesiones pegajosas", donde se "pega" al usuario a un servidor web determinado. En determinados entornos estos es necesario para el funcionamiento correcto de las sesiones, o para maximizar la performance cuando se usan aplicaciones que tienen un alto costo (computacional) de arranque (por ejemplo aplicaciones FastCGI como PHP, Ruby, etc) pero no tan alto de reutilización.
Esto se puede hacer por Cookies o simplemente por IP del usuario que visita. Sin embargo este sistema que se centra en el usuario no tiene muy en cuenta las características de cada servidor de la red, de la misma forma que un LB normal no tienen en consideración las características del usuario.
Esto se puede hacer por Cookies o simplemente por IP del usuario que visita. Sin embargo este sistema que se centra en el usuario no tiene muy en cuenta las características de cada servidor de la red, de la misma forma que un LB normal no tienen en consideración las características del usuario.
Dynamic-Weighted Sticky-Session Load Balancing:Un sistema de estas características hace un balanceo de carga considerando el estado y capacidad de cada servidor de la red, distribuyendo los usuarios de un sitio a lo largo de dicha red de forma que cada usuario se mantenga lo más "pegado" posible a un servidor en la medida que eso sea más beneficioso que moverlo a otro, a fin de mantener los tiempos de respuesta parejos para todos.
Como ven, en esto del balanceo de carga lo importante es tener bien claro cuál es el algoritmo que queremos utilizar y claro, el software que lo implemente.
CACHE:
Junto con el balanceo de carga otro de los elementos más importantes y que se combina siempre que se busca desarrollar sistemas escalables y redundantes es el cacheo de la data más usada.
El cacheo permite hacer un uso más eficiente de los recursos que ya se tienen y consiste fundamentalmente en:
- Almacenar copias de los datos a los que se accede más frecuentemente. Por ejemplo lo que hace MemCached en el tema de las BD y que tanto a ayudado a Facebook con su mysql.
- Generar índices de búsquedas más comunes o frecuentes, lo que ha ayudado enormemente a google. Porque si yo sé que al día se busca el término "Beyonce" 15 000 veces, tiene sentido que guarde el resultado de esas búsqueda y luego no la tengo que volver a ejecutar, solo muestro lo que ya guardé de la primera búsqueda.
Y así hay muchas otras estrategias de cacheo de datos, siempre buscando optmizar los recursos que ya tenemos. En este tema del cacheo es donde se están colando las BD NoSQL como Cassandra.
Las estrategias de cacheo van desde:
- Implementar esto a nivel de aplicación, por lo que hay que desarrollar pensando en este asunto.
- Implementar el cacheo a nivel de BD.
- Implementar el cacheo en memoria, usando la RAM y el HDD.
- Implementar el cacheo de páginas estáticas en servidores web, para no tener que generar la información cada vez que se pida.
A veces hay que decidir en donde realizar el cacheo, si en la aplicación o en la BD:

En este caso la información que más se consulta de la BD es almacenada en un sistema aparte y de más rápido acceso para su disposición para ser usada por el sistema.
La otra variante es el cacheo de la BD:

La solución que más se ve es una mezcla de estos dos enfoques.
En el caso del cacheo en memoria se considera como la solución que más mejora el rendimiento de las aplicaciones al poner todos los datos en memoria. MemCached y Redis son dos ejemplos de este tipo de estrategia.
El problema con todo esto es que esa información que es cacheada tiene un tiempo de vida determinado por su veracidad. Esto es que si guardo determinada información por una semana en la cache y durante esta semana la información cambió en el servidor, entonces lo que le muestro al cliente no es real y ya por ahí tengo un problema. La solución más común para este problema es que cada vez que algo cambie en el servidor sea escrito nuevamente en la cache o que se establezca un margen de tiempo luego del cual la cache expire y se genere nuevamente.
Mientras el balanceo de carga permite distribuir el procesamiento entre los diferentes nodos en que se encuentra distribuida la aplicación y la cache ayuda a hacer un uso más eficiente de los recursos existen situaciones en que la latencia, demora en dar la respuesta a un cliente, no depende de la cache ni del balanceo de carga si no de la funcionalidad en si, que se demora en procesarse. Esto puede dar la impresión de un sistema lento y enojar bastante a los usuarios del sistema al este congelárseles mientras se termina determinada acción.
Procesamiento OffLine
Esta es la solución al problema que mencionaba anteriormente. Se puede ejemplificar a través de una situación en que el cliente hace una petición la cual como parte de su procesamiento implica consultar determinado sistema, que bien puede estar offline, u ocupado en otro procesamiento, por lo que el cliente debe esperar hasta que se pueda procesar su petición. Otro ejemplo son sistemas como Facebook, donde cuando publicamos un mensaje el cual es notificado a todos nuestros contactos, el mismo aparece como publicado a nosotros inmediatamente, mientras la publicación y notificación real ocurre fuera de nuestra linea de tiempo en la ejecución de facebook porque es inaceptable tener que esperar por todo el proceso de notificación para dar por terminada esta tarea a ojos de los usuarios.
La mejor forma de lograr el procesamiento offline es crear colas de mensajes. Donde nuestro sistema puede enviar mensajes a una cola para que sean procesados y dicho procesamiento ocurre fuera de nuestro sistema, en otro que se encarga de esa tarea. Este desacoplamiento permite escalar aun más las soluciones al tiempo que promueve el trabajo asíncrono.

Como se ilustra en la imagen parte del procesamiento de la aplicación desplegada en el Web Server se envía a través de una cola a otro sistema, que extrae la información a procesar, realiza el procesamiento y guarda los resultados en una BD, tal vez notificando a la aplicación de que ha terminado su trabajo para que entonces esta consulte la BD en busca de los resultados.
Otro problema a enfrentar cuando buscamos desarrollar sistemas escalables y redundantes es la necesidad de integración que podemos tener, ya que las aplicaciones no existen solas en una empresa. Generalmente tendremos un montón de aplicaciones que comparten funcionalidades e incluso datos y que acceden a sus propias BD pero que a veces deben de acceder a BD de otras aplicaciones. Estas aplicaciones pueden estar desarrolladas en diferentes plataformas de desarrollo y tecnologías lo que complica el tema de integración.
La solución para este tipo de situaciones es crear una capa intermedia que se encargue de manejar todos estos escenarios y libere al web server de este trabajo, con lo cual la escalabilidad del mismo se verá beneficiada.
Capa de Plataforma
Introducir una nueva capa permite crear una indirección en el funcionamiento de nuestra aplicación. Esto es beneficioso pues ayuda en hacerla redundante. Veamos cómo.

Al interponer una plataforma entre nuestro servidor de aplicación y la BD podemos cambiar en tiempo de ejecución de BD ante una caída de la misma, siempre y cuando esto esté soportado, e incluso podemos abstraernos de las complejidades del acceso a la BD pues de estas tareas se encarga la capa de plataforma. Igual si necesitamos acceder a otros sistemas o recursos en la red la capa de plataforma puede realizar este trabajo con lo que el servidor de aplicaciones sufre menos en cuanto a rendimiento y trabajo.
Otra ventaja de este enfoque ya más a un nivel de proceso de desarrollo es que al abstraer los diferentes acceso a sistemas y recursos permite que varios equipos de desarrollo creen sus aplicaciones utilizando esta capa y sus funcionalidades, e incluso que intercambien especialistas al tener todos los mismos conocimientos.
Como ya dije al inicio esta es solo la entrada que da pie a ver como WSO2 enfoca estos temas así que en la siguiente entrada veremos como la empresa wso2 ha implementado componentes para casi todos estos problemas/soluciones.











Un vistazo a la Arquitectura para sistemas escalables y redundantes.